|
|
一、研究背景
表观遗传学是当今生信研究的一个热点领域,RNA的甲基化修饰也越来越火热。其中,m6A又是最受研究者所关注的。
m6A修饰是一个已经发生甲基化的核糖核苷酸。A表示该位点碱基是腺嘌呤(A),当腺嘌呤的第六位N处发生甲基化,就是m6A。
类似地,常见的RNA甲基化修饰也包括m1A、m5C和m7G,只是碱基和修饰位置不同而已。
不仅是一些顶级期刊,RNA的甲基化修饰相关研究也比较容易发到影响因子在3~10分之间的期刊,既可以积累材料发高分文章,一不小心发个CNS
也可以随便发一篇简单的SCI,可以说是各种上下游目的兼顾,无论是毕业、评职称还是申请课题,都是很好的的选择。
RNA的甲基化修饰既可以发纯生信文章,也可以补充实验干湿结合,也是一个非常不错的方向。
口说无凭,下面我们就去文献的海洋中去找一找,看一看!
来到我们熟悉的Pubmed,搜索关于m6A的文献。输入“((GEO) OR (TCGA)) AND (m6A)”,可以检索到572条结果,今年已发表234篇,相关文章数量近几年直线上升。m6A已经是很成熟的热门领域,但增长势头依然不减。
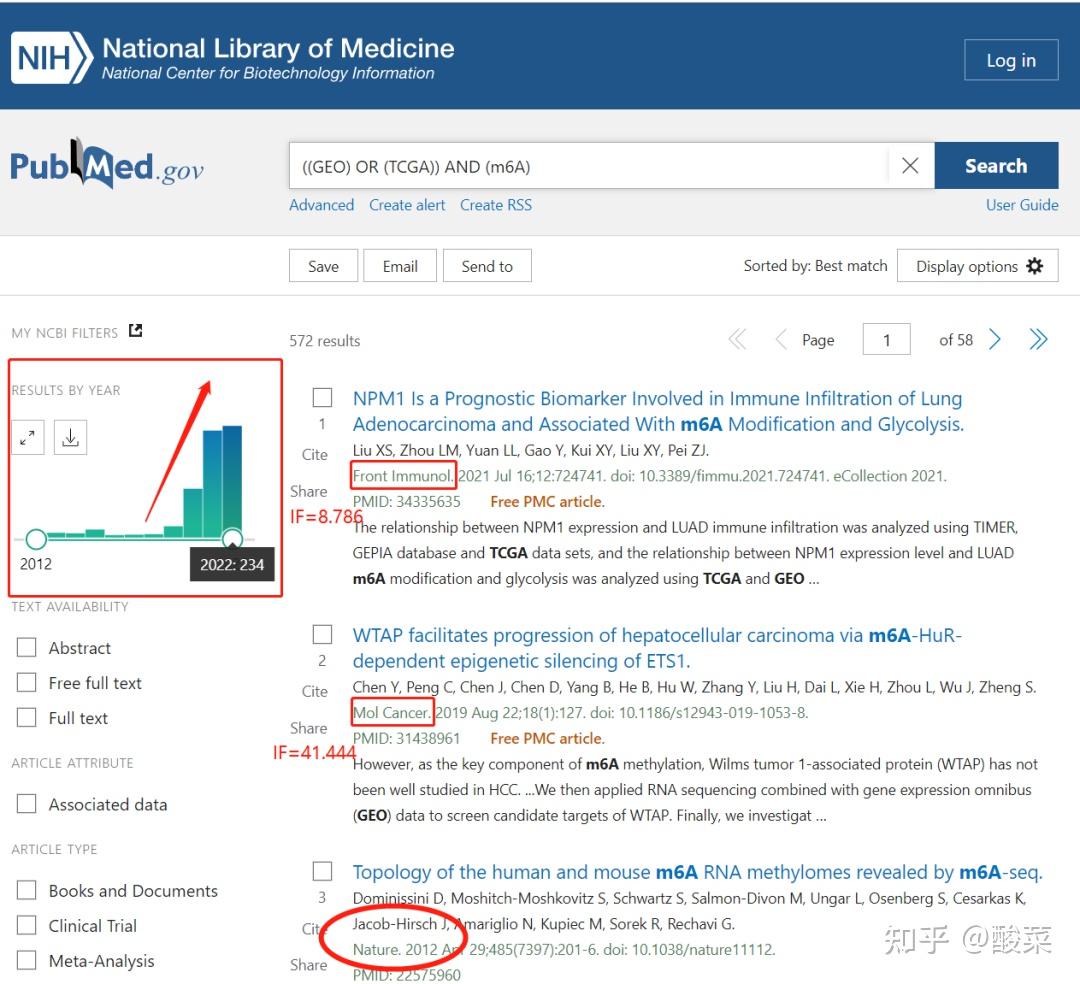
搜索关于m1A的文献。输入“((GEO) OR (TCGA)) AND (m1A)”,可以检索到24条结果,但今年就有12篇!m1A的受关注度可谓暴涨!心动的小伙伴可要抓紧哦!
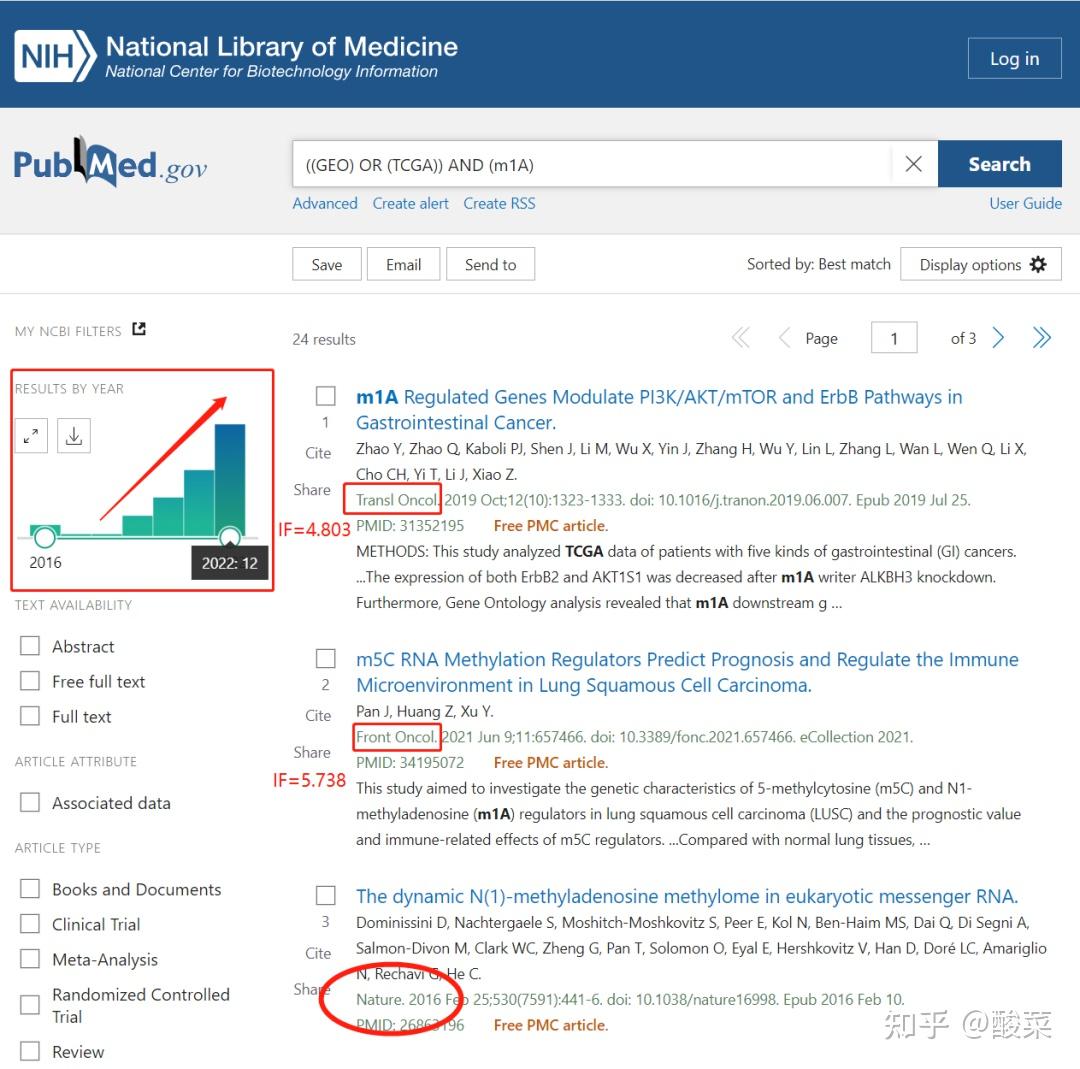
搜索关于m5C的文献。输入“((GEO) OR (TCGA)) AND (m5C)”,可以检索到51条结果,今年就有28篇!m1A的受关注度也在快速增长!
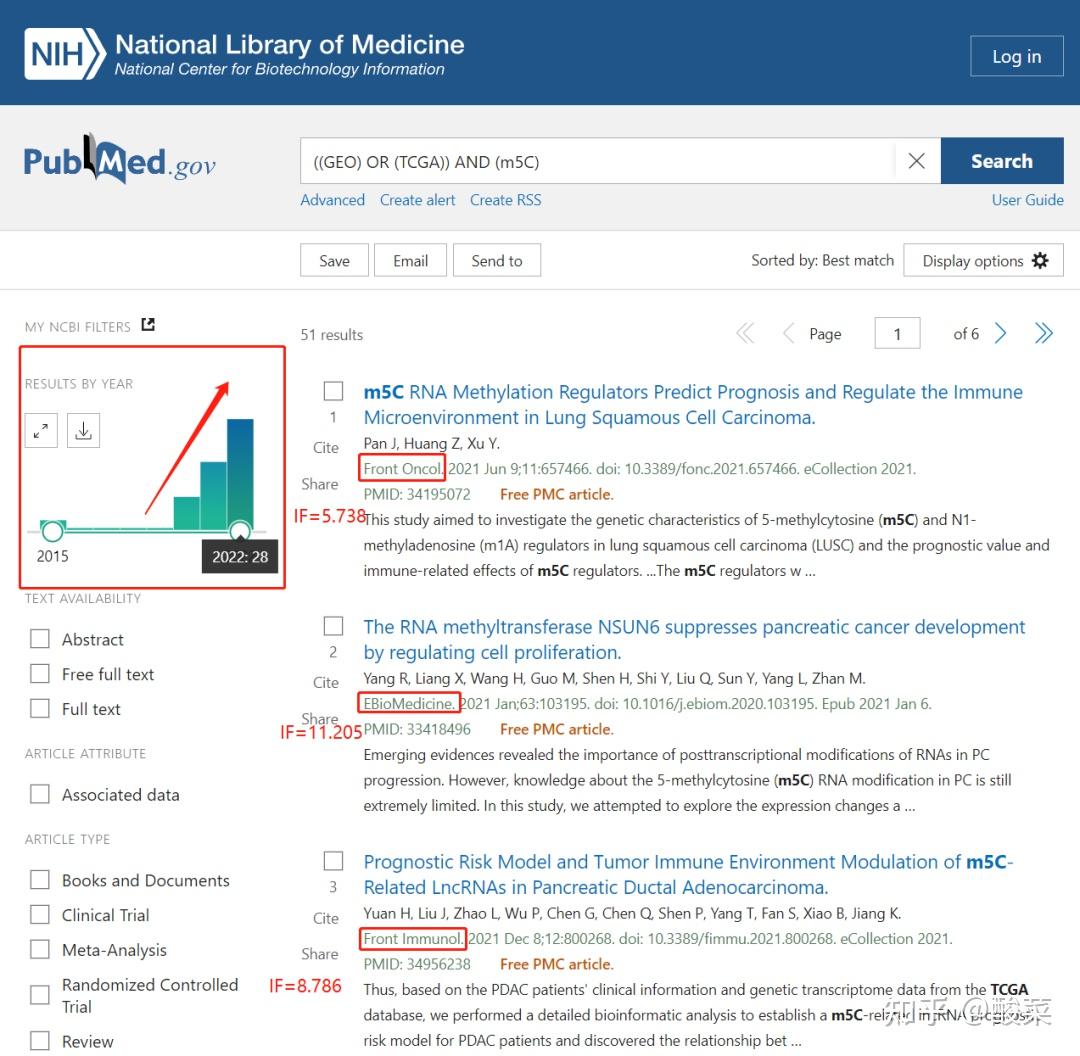
搜索关于m7G的文献。输入“((GEO) OR (TCGA)) AND (m7G)”,可以检索到33条结果,但今年就有29篇!很早以前的2条记录也是侧重转录翻译过程调控机制等纯理论方面。
m7G几乎就是2022年突然冒出来的一个热点方向!
影响因子也稳定保证在3到10之间!
综上可见,RNA甲基化修饰是一个非常值得关注的发文领域,在数据和方法上就满足各种需求的小伙伴!
稳定而又持续增长的热点方向!(不会翻车!求稳!)
刚刚受到关注的“蓝海”领域!(趁着还不那么卷,赶紧投,赶紧发!求新!)
影响因子漂亮!稳定!有保障!
只要网络数据库,我们也可以追热点,发高影响因子文章!
是不是看着很心动?只是不知道自己能不能做。
RNA 的新陈代谢、基因表达的调节以及癌症等人类疾病的发展都需要 RNA 修饰。最近的研究表明,各种 RNA 修饰在癌症中起关键作用。
RNA的修饰受到一些调节因子的作用,当这些调节因子表达发生变化时,RNA的修饰也就发生了变化,对人的身体健康状况也就产生了影响。
我们要做的,就是找出哪些因子的表达发生了变化,造成了怎样的影响。
总而言之,还是老套路:筛表现分子。
先找文献,在前面已经提过,在Pubmed中搜索诸如((GEO) OR (TCGA)) AND (m6A),在搜索到的文献中查看材料方法部分,那里大多会有表型分子清单。


我们选择我们需要的,到时候再引用该文献就可以了。
这些调节因子通常分为三类:
甲基化转移酶(Writers):催化RNA发生m6A甲基化修饰
去甲基化酶(Erasers):介导m6A去甲基化修饰
甲基化阅读蛋白(Readers):识别甲基化修饰信息,参与下游RNA的翻译、降解。
接下来,我们就从以下几篇文献来看看RNA甲基化修饰有多简单!
RNA甲基化名目虽多,但套路大同小异。这里考虑代表性,选两篇(加粗的)文献举例说明。
Chen Z, Zhang Z, Ding W, Zhang J-h, Tan Z-l, Mei Y-r, He W and Wang X-j (2022) Expression and Potential Biomarkers of Regulators for M7G RNA Modification in Gliomas. Front. Neurol. 13:886246.(m7G, IF=4.086)
Xu Z, Chen S, Zhang Y, Liu R, Chen M. Roles of m5C RNA Modification Patterns in Biochemical Recurrence and Tumor Microenvironment Characterization of Prostate Adenocarcinoma. Front Immunol.2022 May 4;13:869759. (m5C, IF=8.786)
Zhao M, Shen S, Xue C. A Novel m1A-Score Model Correlated With the Immune Microenvironment Predicts Prognosis in Hepatocellular Carcinoma. Front Immunol. 2022 Mar 24;13:805967. (m1A, IF=8.786)
Li Q, Ren CC, Chen YN, Yang L, Zhang F, Wang BJ, Zhu YH, Li FY, Yang J, Zhang ZA. A Risk Score Model Incorporating Three m6A RNA Methylation Regulators and a Related Network of miRNAs-m6A Regulators-m6A Target Genes to Predict the Prognosis of Patients With Ovarian Cancer. Front Cell Dev Biol. 2021 Sep 23;9:703969.(m6A, IF=6.081)
二、套路分析
无论怎样的分析,我们都可以归纳到“挑圈联靠”的套路里。
“挑”就是做差异基因分析,挑选出具有差异表达的基因,
证明自己研究立足的基础,用做后续分析
这些都是在之前的文献中已经搜集好的。
以(Li Q et al.,2021)为例,
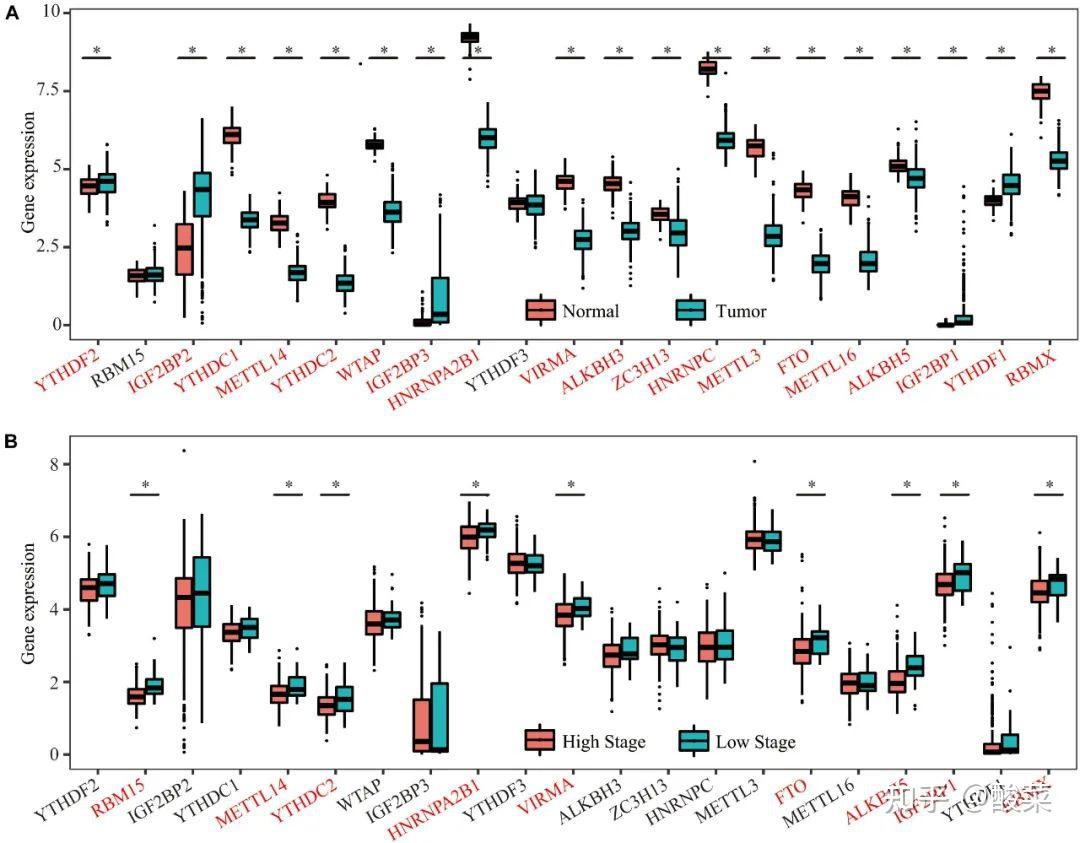
由于是研究疾病,研究者通常会做疾病组织与正常组织的差异表达分析(A),
这样的数据很好获取,如图(A)所示,差异显著基因用红色标注
我们可以从GDC数据库获取患者临床,从来自GTEx数据库获取组织的RNA-seq转录组数据,就可以筛选差异基因。
或者直接比较癌和癌旁(Chen Z et al.,2022)
接下来就可以针对患者样本的不同分组,进一步筛选决定不同因素的基因。例如在(Li Q et al.,2021)中,研究对象是卵巢癌,所以这个分组是癌症的早晚期,也就是发展阶段(B),差异显著基因用红色标注。这里是箱线图。
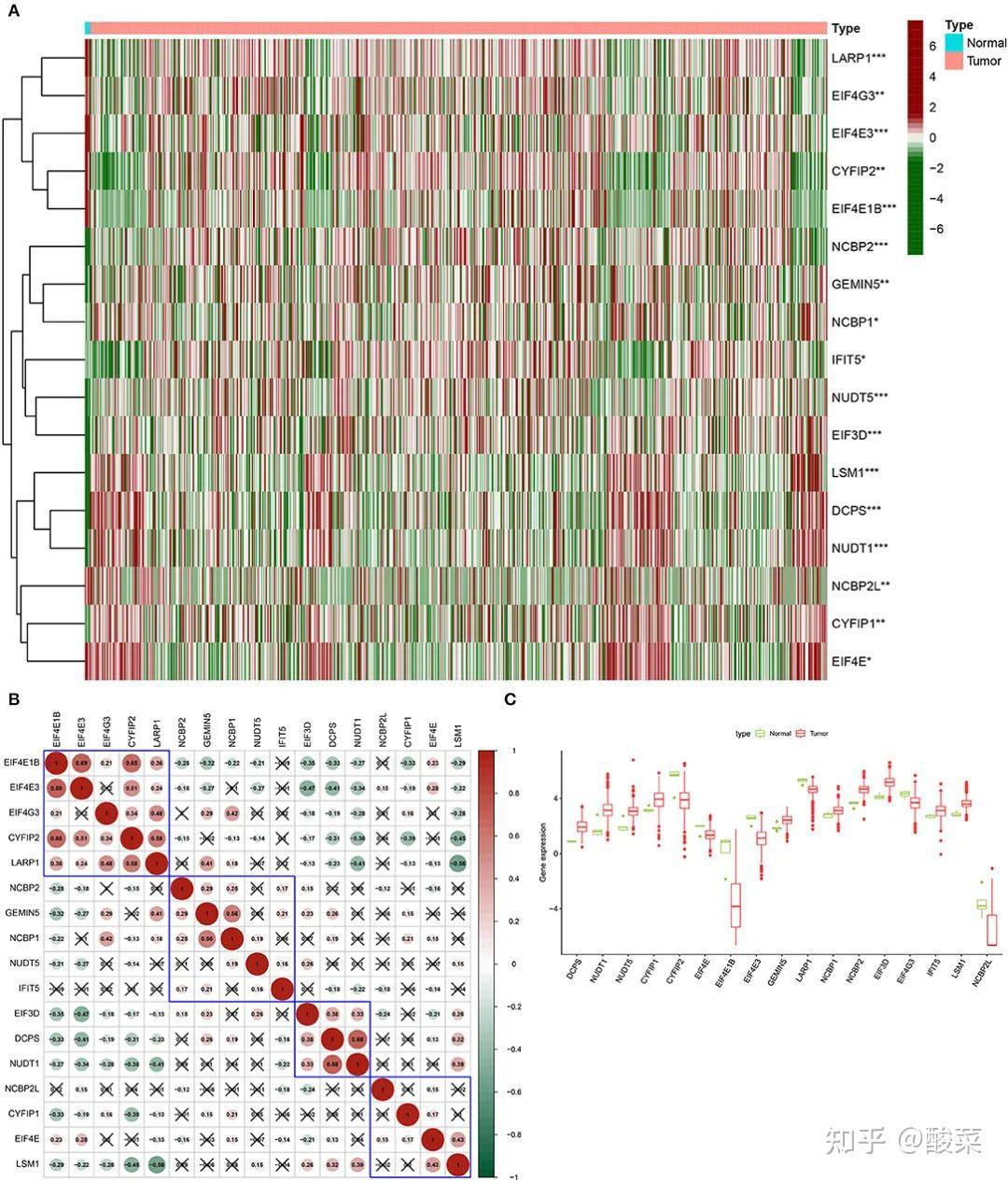
我们也可以同时绘制不同组织间的热图(A)、相关性分析(B)和箱线图(C),让研究结果更丰富(Chen Z et al.,2022)
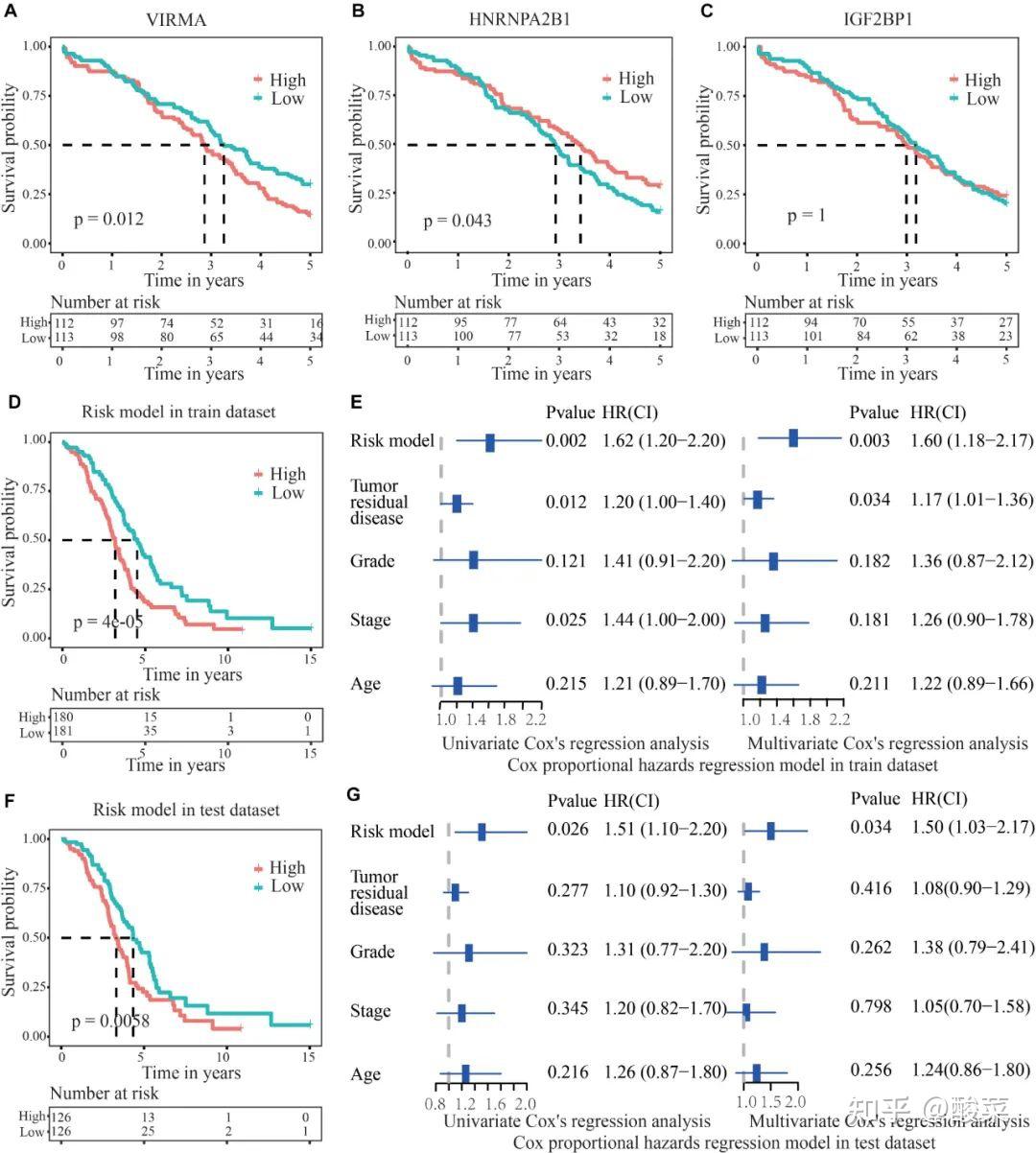
接下来的重头戏包括“靠”,也就是研究的现实意义——临床应用。
研究者会对有差异表达的基因进行LASSO Cox回归算法,筛选出基因为变量获得风险评分模型。
做KM生存曲线分析(ABCDF),评估生存率。
对OC患者进行了单变量和多变量分析,评估临床病理特征是否是患者预后的独立因素。
总之,证明这些基因具有预后意义,可以作为生物标志物。
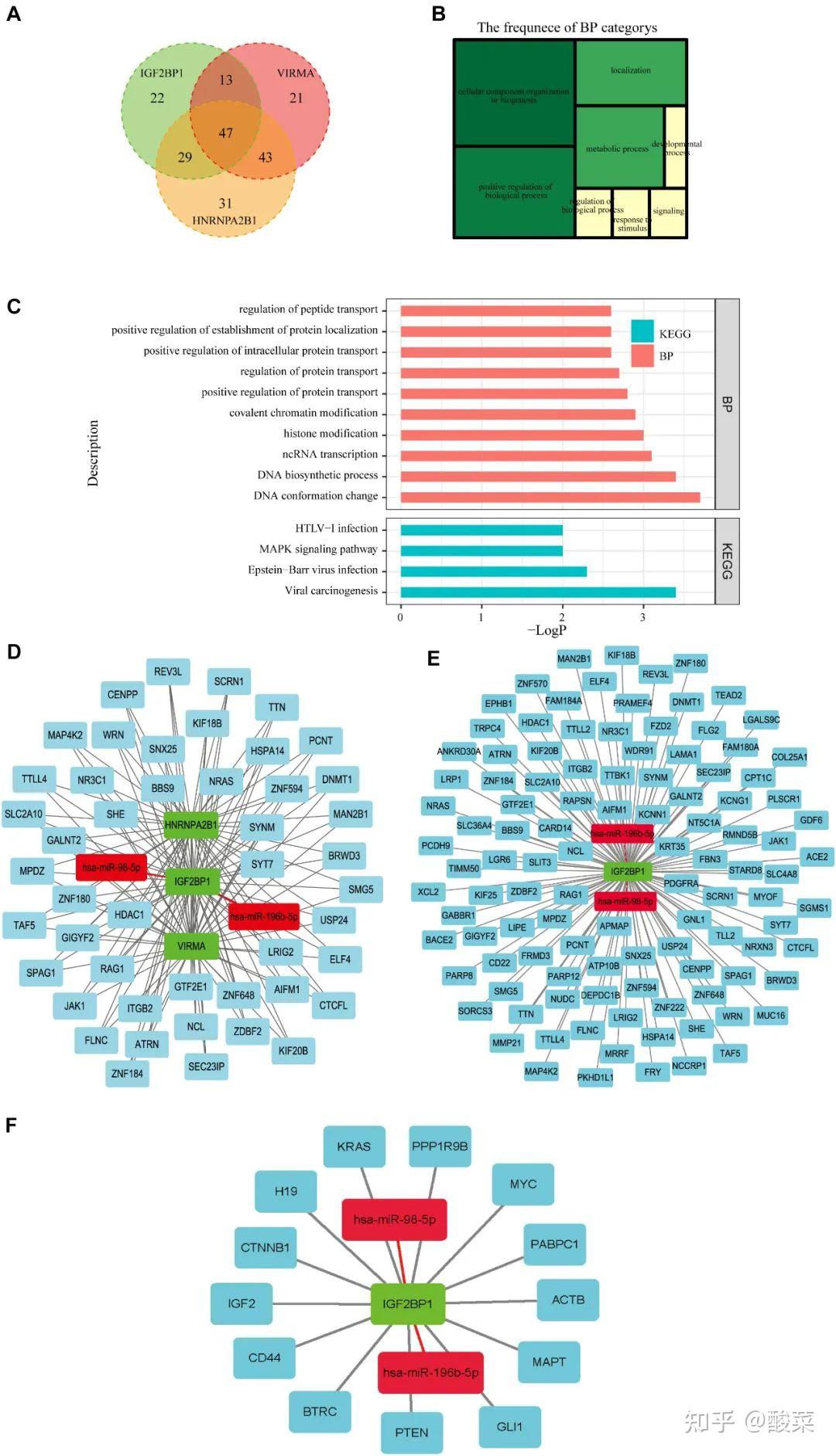
最后会基于这些选定的标志分子,仍以(Li Q et al.,2021)为例,
在数据库中选择与表型分子相关的靶基因(A),做GO和KEGG功能富集分析(B、C),也就是“圈”
最后“联”
构建miRNAs-m6A调控基因-m6A靶基因调控网络(D-F),将20多个调控因子分为不同的作用途径。
RNA的甲基化修饰看似复杂,最终还是逃脱不了这样的研究目的和研究思路,一切被归纳到“挑圈联靠”之中。
虽然经常上顶级期刊,发文通常分数也很高,但分析内容都是很常规的,很简单的。
小伙伴们有没有很心动呢?
这样的成功很好复制!
我们为大家精心准备了彩蛋环节!
在我们挑圈联靠,就可以提供这些生信分析服务,而且远不止示例所举的这些最常规的分析项目!
想进一步走上发高分,通过人生巅峰的小伙伴欢迎添加我们销售的微信进一步了解!
作者:三叶虫
本文首发于“ 解螺旋”微信公众号
转载请注明:解螺旋·临床医生科研成长平台
 |
|



 发表于 2022-10-3 10:36:28
发表于 2022-10-3 10:36:28